分析技术研习室
课题组每周研讨会
第二期 程序控制与数据操作流
推荐图书
- 《R for Data Science》
- 《R 语言编程指南》
- 《R 实战》
- 其他推荐见:https://shixiangwang.gitee.io/geek-r-tutorial/expand-reading.html
其他资料
R 编程基础
- https://shixiangwang.gitee.io/geek-r-tutorial/base.html
内容:
- 基础语法
- 控制与循环结构
- 函数与包
- 数据读取和保存
read.*与write.*load与savereadRDS与saveRDS
数据操作流程
- 放本小抄在身边,随时查阅
Tidyverse
-
https://github.com/tidyverse/
-
数据导入
read_* -
管道
%>%x %>% f(y)>f(x, y)
-
筛选
- 行筛选
slice,filter,sample_n,sample_frac,top_n,distinct - 列筛选
selectcontainsnum_rangestarts_withends_withone_ofmatches
- 排序
arrange
- 行筛选
-
行列增加/更新
mutate,transmutemutate_add_rowadd_columnrenamerownames_to_column,column_to_rowname- 向量化函数
- 基本的数学和比较逻辑运算符
+ - * / > < == - 偏移
dplyr::laglead - 聚合
dplyr::cumallcumanycummaxcummeancummincumprodcumsum - 排序
dplyr::cume_distdense_rankmin_rankntilepercent_rankrow_number - 其他
dplyr::betweencase_whencoalesceif_elsena_ifpmaxpminrecoderecode_factor
- 基本的数学和比较逻辑运算符
-
汇总
- 简单汇总
countsummarize
- 分组汇总
group_by,ungroup - 汇总函数
- 计数
dplyr::nn_distinctbase::sum(!is.na()) - 位置
mean,meadian - 逻辑值
mean,sum - 位置
dplyr::firstlastnth - 排序
quantileminmax - 分布
IQRmadsdvar
- 计数
- 简单汇总
-
合并
bind_rowsbind_colssemi_joinanti_joinleft_join,right_join,inner_join,full_joinintersectsetdiffunionsetequal辅助查看两个数据集是否相同(不管行序)
-
变异动词 (
_at,_if,_all)filter_*select_*summarize_*arrange_*- …
-
字符处理
substrstringr包与正则表达式略微复杂,可以单独讲一次
- 转换 tidyr
-
Tidy 数据格式

tibbletribble,enframeas_tibble,is_tibble
- 缺失值
drop_nafillreplace_na
-
长转宽
pivot_wider,spread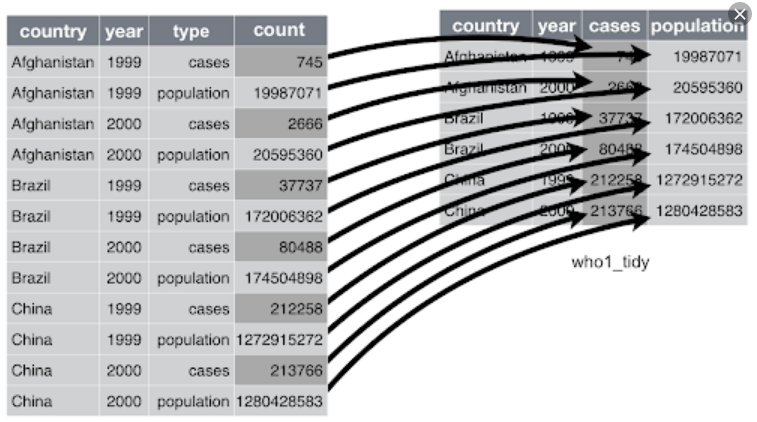
-
宽转长
pivot_longer,gather
- 拓展表格
expandcomplete
- 分割和连接
separateseparate_rowsunite
-
-
数据导出
write_*
data.table 与 base
- 数据导入
fread - 数据导出
fwrite - data.table 语法
dt[i, j, by] - 数据过滤与合并等操作与 R 基础语法一致,也可以使用 tidyverse 处理
- 整数索引
- 逻辑索引
- 命名索引
- 进一步的学习参考小抄、文档和《R 语言编程指南》
本期未讲述的内容???
- 正则表达式与字符串处理:
base与stringr - 列表处理与迭代计算:
purrr - 统计建模:
stats与broom - 绘图:
graphics与ggplot2 - 函数编程:
apply家族和purrr等
后几期主题
开发:
- devtools
- usethis
- testthat
- roxygen2 与 roxytest