分析技术研习室
课题组每周研讨会
data.table
data.table的基本框架

图片引自:https://rstudio.com/
创建data.table
-
setDT()setDT()适用于对’list’, ‘data.table’, ‘data.frame’这三种类型,它比as.data.table要快,是以传地址的方式直接修改对象。> fruit = data.frame(x=rep(c("apple","banana","orange"),each=2), y=c(1,3,6), z=1:6) x y z 1 apple 1 1 2 apple 3 2 3 banana 6 3 4 banana 1 4 5 orange 3 5 6 orange 6 6 > class(fruit) [1] "data.frame" > setDT(fruit) > class(fruit) [1] "data.table" "data.frame" -
as.data.table()as.data.table()的适用范围更广 -
data.table::copy(<DATA>)复制数据起一个新的名字,因为data.table的部分函数在使用的过程中会直接对原来的数据进行改写,为了防止原来的数据被改变,使用拷贝的文件。
> dt <- data.table::copy(fruit) x y z 1: apple 1 1 2: apple 3 2 3: banana 6 3 4: banana 1 4 5: orange 3 5 6: orange 6 6 -
setnames(x,old,new)设置x的列名> setnames(dt, c("x","y","z"), c("name", "number", "money")) > dt name number money 1: apple 1 1 2: apple 3 2 3: banana 6 3 4: banana 1 4 5: orange 3 5 6: orange 6 6 -
setcolorder(x,neworder)重新安排列的顺序
> setcolorder(dt, c("name", "money", "number")) > dt name money number 1: apple 1 1 2: apple 2 3 3: banana 3 6 4: banana 4 1 5: orange 5 3 6: orange 6 6
对行 i 进行操作
-
按条件选择行
<、>、<=、>=、%in%、!、&、|、%like%、%between%、==、is.na()、!is.na()…> dt[name == "banana",] name money number 1: banana 3 6 2: banana 4 1> dt[name %like% "e",] name money number 1: apple 1 1 2: apple 2 3 3: orange 5 3 4: orange 6 6> dt[number %between% c(3,7),] name money number 1: apple 2 3 2: banana 3 6 3: orange 5 3 4: orange 6 6
对列 j 进行操作
-
按条件选取列
- 选择或删除某列
> dt[,2] money 1: 1 2: 2 3: 3 4: 4 5: 5 6: 6> dt[, -2] name number 1: apple 1 2: apple 3 3: banana 6 4: banana 1 5: orange 3 6: orange 6> dt[, c("name", "number")] name number 1: apple 1 2: apple 3 3: banana 6 4: banana 1 5: orange 3 6: orange 6使用
c("<name of col1>", "<name of col2>")和.(col1, col2)效果一样> dt[, .(name, number)] name number 1: apple 1 2: apple 3 3: banana 6 4: banana 1 5: orange 3 6: orange 6> dt[max(number),] d e c name money number 1: 2 1 expensive orange 6 6 -
对列进行计算
- 基本计算
sum()、mean()、median()、min()、max()…> dt[, .(x = sum(number))] x 1: 20-
添加列
:=直接在原数据上增加新列或替换旧列> dt[name == "apple", c := 1+2] > dt[name == "apple", c := 1+4] > dt name money number c 1: apple 1 1 3 2: apple 2 3 3 3: banana 3 6 3 4: banana 4 1 3 5: orange 5 3 3 6: orange 6 6 3替换时可以增加条件语句
> dt[, c := ifelse(money < 4, "cheap", "expensive")] > dt d e c name money number 1: 2 0 cheap apple 1 1 2: 2 -2 cheap apple 2 3 3: 2 0 expensive banana 4 1 4: 2 2 cheap banana 3 6 5: 2 0 expensive orange 5 3 6: 2 1 expensive orange 6 6同时增加两个及以上的列,有两种写法:
- 直接写法
> dt[, `:=` (c = 1, d = 2)] > dt name money number c d 1: apple 1 1 1 2 2: apple 2 3 1 2 3: banana 3 6 1 2 4: banana 4 1 1 2 5: orange 5 3 1 2 6: orange 6 6 1 2-
list写法
> dt[, c("c", "d") := list(1, 2)]
-
删除列
> dt[, c := NULL] > dt name money number d 1: apple 1 1 2 2: apple 2 3 2 3: banana 3 6 2 4: banana 4 1 2 5: orange 5 3 2 6: orange 6 6 2 -
更改某列的数据类型
as.integer()、as.numeric()、as.character()、as.Date()…> dt[, d := rnorm(6)] > dt name money number d 1: apple 1 1 0.7079005 2: apple 2 3 -2.6720810 3: banana 3 6 2.3955292 4: banana 4 1 0.1127583 5: orange 5 3 -0.1899854 6: orange 6 6 1.5170863 > dt[, e := as.integer(d)] > dt name money number d e 1: apple 1 1 0.7079005 0 2: apple 2 3 -2.6720810 -2 3: banana 3 6 2.3955292 2 4: banana 4 1 0.1127583 0 5: orange 5 3 -0.1899854 0 6: orange 6 6 1.5170863 1
用by进行分组
-
基本操作
- 分组
> dt[, name, by = .(number)] number name 1: 1 apple 2: 1 banana 3: 3 apple 4: 3 orange 5: 6 banana 6: 6 orange-
每组进行计算
> dt[, .(c = sum(money)), by = number] number c 1: 1 5 2: 3 7 3: 6 9> dt[, c:= sum(money), by = number] > dt name money number d e c 1: apple 1 1 0.7079005 0 5 2: apple 2 3 -2.6720810 -2 7 3: banana 3 6 2.3955292 2 9 4: banana 4 1 0.1127583 0 5 5: orange 5 3 -0.1899854 0 7 6: orange 6 6 1.5170863 1 9 -
取分组后每组的首行
> dt[, .SD[1], by = number] number name money d e c 1: 1 apple 1 0.7079005 0 5 2: 3 apple 2 -2.6720810 -2 7 3: 6 banana 3 2.3955292 2 9 -
取分组后每组的尾行
> dt[, .SD[.N], by = number] number name money d e c 1: 1 banana 4 0.1127583 0 5 2: 3 orange 5 -0.1899854 0 7 3: 6 orange 6 1.5170863 1 9
data.table的常用函数
-
setcolorder(x,neworder)重新安排列的顺序> setcolorder(dt, c("d","e","c","name", "money", "number")) > dt d e c name money number 1: 0.1127583 0 5 banana 4 1 2: 0.7079005 0 5 apple 1 1 3: -0.1899854 0 7 orange 5 3 4: -2.6720810 -2 7 apple 2 3 5: 1.5170863 1 9 orange 6 6 6: 2.3955292 2 9 banana 3 6 -
setorder(x, order1, -order2)重新安排行的顺序先对order1进行升序,再在order1的基础上对order2进行降序
> setorder(dt, number, -money) > dt name money number d e c 1: banana 4 1 0.1127583 0 5 2: apple 1 1 0.7079005 0 5 3: orange 5 3 -0.1899854 0 7 4: apple 2 3 -2.6720810 -2 7 5: orange 6 6 1.5170863 1 9 6: banana 3 6 2.3955292 2 9 -
unique()去除重复- 根据by这列提取非重复的行
uniqueN(dt, by = c(""))计数非重复的行
> unique(dt, by = c("name"))
d e c name money number
1: 0.1127583 0 5 banana 4 1
2: 0.7079005 0 5 apple 1 1
3: -0.1899854 0 7 orange 5 3
> uniqueN(dt, by = c("name"))
[1] 3
-
key(dt, colname)设置索引 -
setkey(dt, NULL)去除索引⚠️:当提取的索引是数字时格式不同
> setkey(dt, name) > dt d e c name money number 1: -2.6720810 -2 7 apple 2 3 2: 0.7079005 0 5 apple 1 1 3: 0.1127583 0 5 banana 4 1 4: 2.3955292 2 9 banana 3 6 5: -0.1899854 0 7 orange 5 3 6: 1.5170863 1 9 orange 6 6 > dt["banana", ] d e c name money number 1: 0.1127583 0 5 banana 4 1 2: 2.3955292 2 9 banana 3 6> setkey(dt, c) > dt["7", ] Error in bmerge(i, x, leftcols, rightcols, roll, rollends, nomatch, mult, : Incompatible join types: x.c (integer) and i.V1 (character) Called from: bmerge(i, x, leftcols, rightcols, roll, rollends, nomatch, mult, ops, verbose = verbose) Browse[1]> Q > dt[.(7)] d e c name money number 1: -2.6720810 -2 7 apple 2 3 2: -0.1899854 0 7 orange 5 3- 可以设置多个索引
> setkey(dt, number, name) > dt d e c name money number 1: 0.7079005 0 5 apple 1 1 2: 0.1127583 0 5 banana 4 1 3: -2.6720810 -2 7 apple 2 3 4: -0.1899854 0 7 orange 5 3 5: 2.3955292 2 9 banana 3 6 6: 1.5170863 1 9 orange 6 6-
针对索引进行筛选
⚠️:
roll = TRUE没有的信息用上一条代替⚠️:
roll = -Inf没有的信息用下一条代替
> dt[.(3,"apple")] d e c name money number 1: -2.672081 -2 7 apple 2 3 > dt[.("orange", 3:6)] d e c name money number 1: -0.1899854 0 7 orange 5 3 2: NA NA NA orange NA 4 3: NA NA NA orange NA 5 4: 1.5170863 1 9 orange 6 6 > dt[.("orange", 3:6), roll = TRUE] d e c name money number 1: -0.1899854 0 7 orange 5 3 2: -0.1899854 0 7 orange 5 4 3: -0.1899854 0 7 orange 5 5 4: 1.5170863 1 9 orange 6 6 > dt[.("orange", 3:6), roll = -Inf] d e c name money number 1: -0.1899854 0 7 orange 5 3 2: 1.5170863 1 9 orange 6 4 3: 1.5170863 1 9 orange 6 5 4: 1.5170863 1 9 orange 6 6 > dt[.("orange", 3:6), nomatch = 0] d e c name money number 1: -0.1899854 0 7 orange 5 3 2: 1.5170863 1 9 orange 6 6 > dt[!.("orange", 3)] d e c name money number 1: 0.7079005 0 5 apple 1 1 2: -2.6720810 -2 7 apple 2 3 3: 0.1127583 0 5 banana 4 1 4: 2.3955292 2 9 banana 3 6 5: 1.5170863 1 9 orange 6 6-
检查索引
haskey(dt): 返回逻辑值,检查是否存在索引key(dt):检查索引内容
> haskey(dt)
[1] TRUE
> key(dt)
[1] "number" "name"
可以使用索引简化计算
举例1:计算name为apple所在行的number值总和
> setkey(dt, name)
> dt["apple", sum(number)]
[1] 4
> dt
d e c name money number
1: 0.7079005 0 5 apple 1 1
2: -2.6720810 -2 7 apple 2 3
3: 0.1127583 0 5 banana 4 1
4: 2.3955292 2 9 banana 3 6
5: -0.1899854 0 7 orange 5 3
6: 1.5170863 1 9 orange 6 6
举例2:按照name分组计算number之和(没有索引也可以做)
使用索引
> setkey(dt, name)
> dt[c("apple","banana","orange"), sum(number), by = .EACHI]
name V1
1: apple 4
2: banana 7
3: orange 9
> dt[c("apple","banana","orange"), sum(number)]
[1] 20
不使用索引
> dt[, sum(number), by =name]
name V1
1: apple 4
2: banana 7
3: orange 9
组合data.table
-
按相同的列内容进行data.table组合
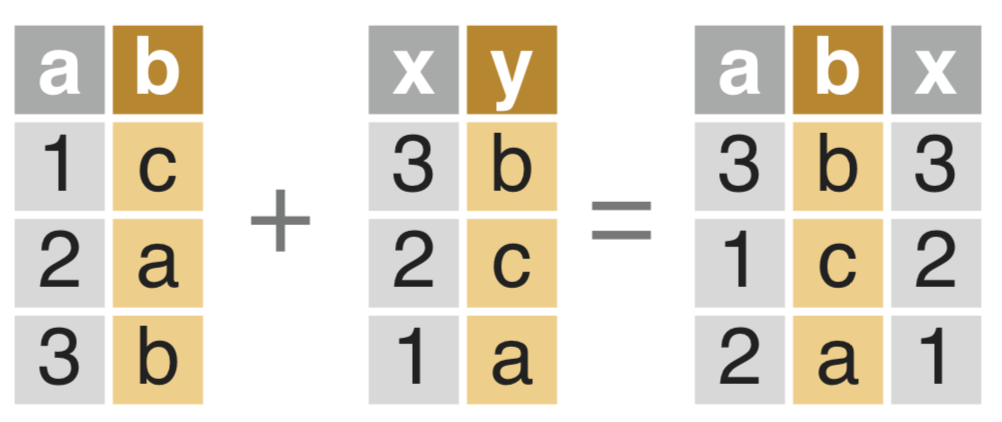
> dt_a <- data.table(a = 1:3,
+ b = c("c","a","b"))
> dt_a
a b
1: 1 c
2: 2 a
3: 3 b
> dt_b <- data.table(x = rev(1:3),
+ y = c("b","c","b"))
> dt_b
x y
1: 3 b
2: 2 c
3: 1 b
> dt_a[dt_b, on = .(b = y)]
a b x
1: 3 b 3
2: 1 c 2
3: 3 b 1
条件选择组合
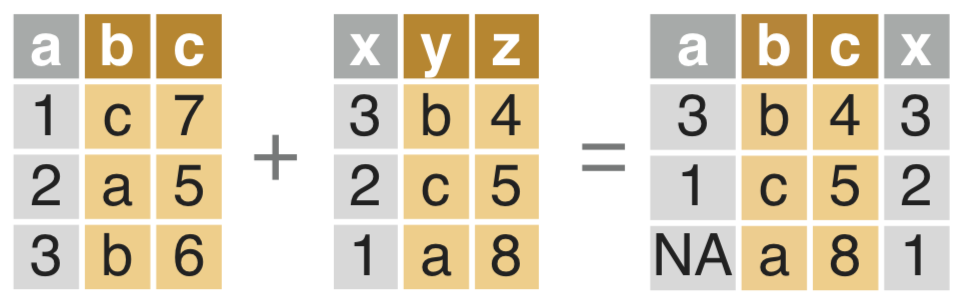
> dt_a[dt_b, on = .(b = y)]
a b c x z
1: 3 b 6 3 4
2: 1 c 7 2 5
3: 2 a 5 1 8
> dt_a[dt_b, on = .(b = y, c > z)]
a b c x
1: 3 b 4 3
2: 1 c 5 2
3: NA a 8 1
-
bind组合两个data.table
-
rbind()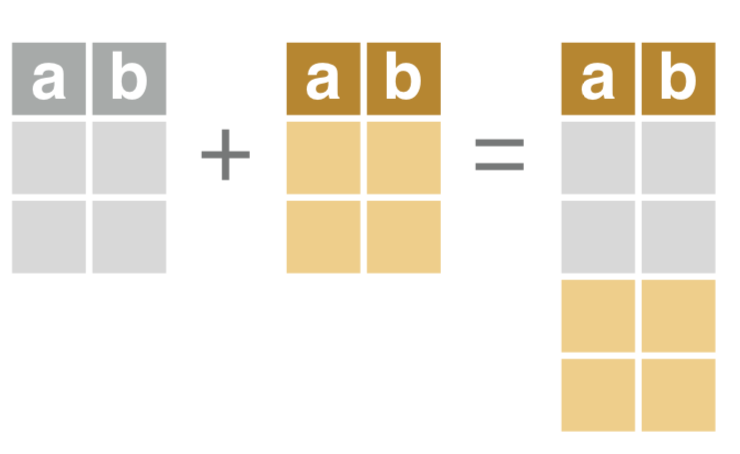
> dt_a a b 1: 1 c 2: 2 a 3: 3 b > dt_b a b 1: 3 x 2: 2 y 3: 1 z > rbind(dt_a, dt_b) a b 1: 1 c 2: 2 a 3: 3 b 4: 3 x 5: 2 y 6: 1 zcbind()
-
读取或写出文件
-
fread("<name>.csv", select = c("a","b"))读取.csv或.tsv格式的文件,可以选择特定列读取 -
fwrite(dt, "<name>.csv")输出R环境中名为dt的数据框为.csv文件
foverlaps()
-
foverlaps()格式
foverlaps(x, y, by.x = if (!is.null(key(x))) key(x) else key(y),
by.y = key(y), maxgap = 0L, minoverlap = 1L,
type = c("any", "within", "start", "end", "equal"),
mult = c("all", "first", "last"),
nomatch = getOption("datatable.nomatch", NA),
which = FALSE, verbose = getOption("datatable.verbose"))
看两个数据框区域是否存在overlap,使用y作为索引去x中寻找有overlap的情况
> x = data.table(chr=c("Chr1", "Chr1", "Chr2", "Chr2", "Chr2"),
+ start=c(5,10, 1, 25, 50), end=c(11,20,4,52,60))
> x
chr start end
1: Chr1 5 11
2: Chr1 10 20
3: Chr2 1 4
4: Chr2 25 52
5: Chr2 50 60
> y = data.table(chr=c("Chr1", "Chr1", "Chr2"), start=c(1, 15,1),
+ end=c(4, 18, 55), geneid=letters[1:3])
> y
chr start end geneid
1: Chr1 1 4 a
2: Chr1 15 18 b
3: Chr2 1 55 c
> setkey(y, chr, start, end)
> foverlaps(x, y, type="any")
chr start end geneid i.start i.end
1: Chr1 NA NA <NA> 5 11
2: Chr1 15 18 b 10 20
3: Chr2 1 55 c 1 4
4: Chr2 1 55 c 25 52
5: Chr2 1 55 c 50 60
type
type = "within" 只匹配y的区域完全包含在x的区域内的情况(相等也属于within)
type = "any" 匹配y和x有重叠的区域
type = "start" 匹配start一样的情况
type = "end"匹配end一样的情况
…
- 其他
nomatch = NULL 返回匹配得上的部分
setkey() 设置匹配索引
参数which = TRUE 是只返回两个数据框匹配情况的行号
参数mult = "first" 是返回x中第一次匹配上的行
foverlaps(x, y, type="any", mult="first")
⚠️:如果x和y索引的列名称不同时,在foverlaps()内加上一行参数
by.x =c("", "", "") 对应y中列的名称
数据的拆分和合并
melt()dcast()
> reshape_dt <- data.table(kinds = c(rep("peach", 2), rep("grape", each = 2)),
price = c("3","8","4","6"),
price2 = c("4","9","5","7"),
level = c("h","l","h","l"))
> reshape_dt
kinds price price2 level
1: peach 3 4 h
2: peach 8 9 l
3: grape 4 5 h
4: grape 6 7 l
> reshape_dt_new <- melt(reshape_dt, id.vars = c("kinds", "level"),
measure.vars = c("price", "price2"),
variable.name = "2price",
value.name = "money")
> reshape_dt_new
kinds level 2price money
1: peach h price 3
2: peach l price 8
3: grape h price 4
4: grape l price 6
5: peach h price2 4
6: peach l price2 9
7: grape h price2 5
8: grape l price2 7
> dcast(reshape_dt_new, kinds + level ~ `2price`, value.var = "money")
kinds level price price2
1: grape h 4 5
2: grape l 6 7
3: peach h 3 4
4: peach l 8 9