分析技术研习室
课题组每周研讨会
支持向量机(SVM)
学习资料来源:https://zhuanlan.zhihu.com/p/24998882
前言
支持向量机(Support Vector Machine SVM)是一种监督式的学习方法,可广泛地应用在统计分类问题中(当然也可用于回归分析)。经过多年的发展与实际应用,SVM一直被认为是效果最好的现成可用的分类算法之一,同时也是机器学习中最为经典的算法之一。
<Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow>
It is one of the most popular models in Machine Learning, and anyone interested in Machine Learning should have it in their toolbox. SVMs are particularly well suited for classification of complex small- or medium-sized datasets.
定义
支持向量机的基本模型是定义在特征空间上的间隔最大的分类器(包括线性和非线性),这类分类器的特点就是它们能够同时最小化经验误差与最大化几何边缘区,因此支持向量机也被称为最大边缘区分类器。
假设数据是线性可分的,那么我们可以选择分离两类数据的两个平行超平面,此时它们之间的距离达到尽可能的大,在这两个超平面范围内的区域称为间隔(margin) ,线性可分下的间隔也被称为”硬间隔”(区别于近似线性可分下的软间隔),最大间隔超平面就是位于它们正中间的超平面
“支持向量”这个概念,通常,在一个数据集中有着无数的样本点,但SVM算法并非是以所有的样本点作为构建超平面的依据,可以构建的超平面有无穷多个,但具有最大间隔的超平面才是SVM要寻找的最优解,同时伴随产生两个平行超平面,即上图中的两条虚线,这两条虚线所穿过的样本点,就是SVM中的支持样本点,称为“支持向量”,实际上最优超平面的方向和位置完全取决于选择哪些样本作为支持向量。
线性支持向量机(林轩田)
讲线性支持向量机之前先讲一下感知机学习算法(PLA)
感知机(Perceptron)在1957年由Rosenblatt提出,是神经网络和支持向量机的基础。感知机是一种二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,+1代表正类,-1代表负类。感知机属于判别模型,它的目标是要将输入实例通过分离超平面将正负二类分离。
信用卡的例子(给或者不给信用卡):
将不同的条件按照W权重去计算得到score,如果超过某个值就给信用卡,如果没有就不给。公式就是
wx-threshole,大于零就给,小于零就不给。
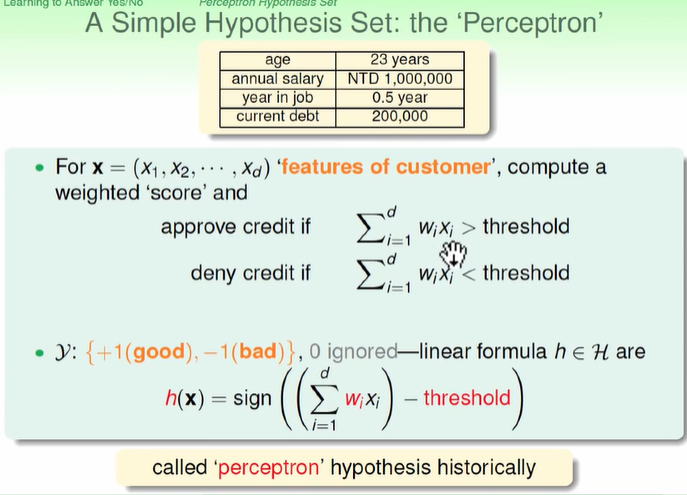
sign()
(在数学和计算机运算中,其功能是取某个数的符号(正或负): 当x>0,sign(x)=1;当x=0,sign(x)=0; 当x<0, sign(x)=-1; 在通信中,sign(t)表示这样一种信号: 当t≥0,sign(t)=1; 即从t=0时刻开始,信号的幅度均为1; 当t<0, sign(t)=-1;在t=0时刻之前,信号幅度均为-1.)
可能哪个条件比较重要那么给的权重就比较大,如果哪个条件是负相关的,那么就给个负值的权重。
不同的w不同的门槛就找到不同的H;H其实就是感知机;
上面就找到了可能的hypothesis.
但是我们并没有找到最终的完美的预测函数,那么怎么找到最佳的H?

PLA (perception learning algorithm)感知机学习算法
(知错能改演算法)从一个w开始,发现错误就改正

PLA什么时候会停下来:找到最佳的线的时候
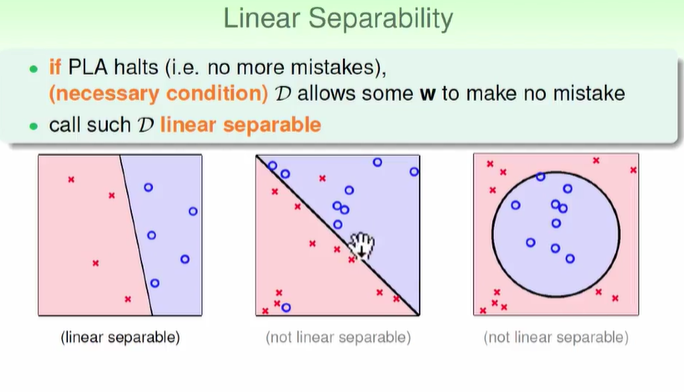
但是如果遇到线性不可分的情况可能不会停下来:那么我们的PLA到底会不会停下来??
假设我们有一个wf可以完美的将圈叉分开;
yn的值是正负,同号相乘为正,所以如果你的线正好完美对应,那么最小的ynwfxn会大于零。wf与PLA找到的wt的关系,wfwt两个向量到底接不接近?如果两个向量做内积,内积的值越大,那么两个向量就越接近。下面的公式中可以看出来更新的过程中,两个向量的乘积会越来越大。

但是PLA还有一个条件是只有遇到错误的时候才会更新,下面利用这个性质来讲解更新的最大的长度,以及更新的速度不会很快。

所以我们从w0开始更新到wT的过程中,内积会越来越大,两个向量也会越来越接近,慢慢的靠近;不会无限制的增长,增长的最大的长度是Xn,会停下来。
####################################################
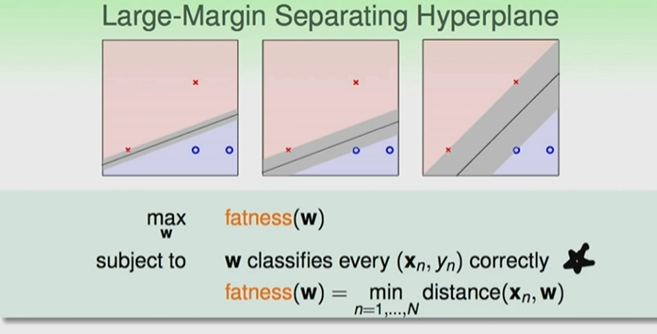
大间距分离超平面
PLA 找到最合适的线;下面的三条线都可以很好的把训练资料分开;但是哪一条线是最好的呢?
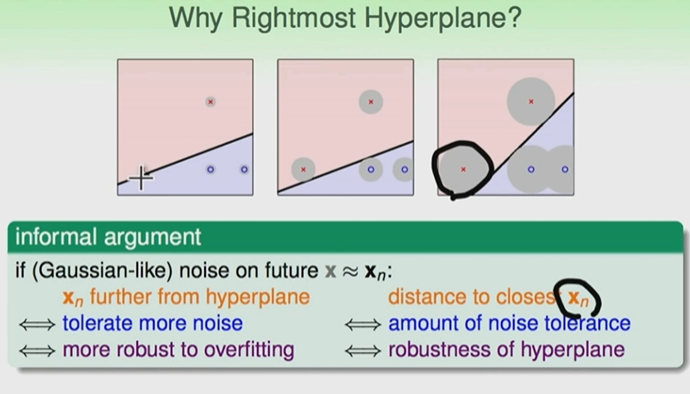
测量误差的容忍度:如果点与线离的距离很远的话,那么我们可以说这条线可以忍受越多的测量误差
同样我们找到的线要与所有的点距离越远越好,那么这条线容忍的误差也会越多
换一种说法就是我们要找到最胖的那条线
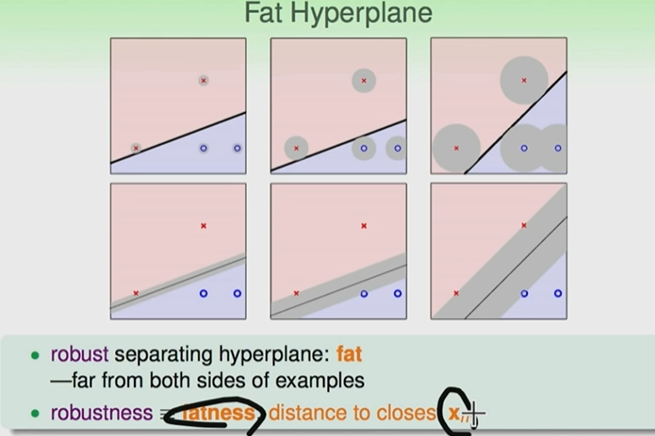
那么我们要找到的线就要满足下面两个条件:找到合适的线,可以把圈圈叉叉分开的线,计算每条线与点的距离,找到点与线的最小的距离,比较所有的线与点的最小距离,找到最大的值就是最合适的线。
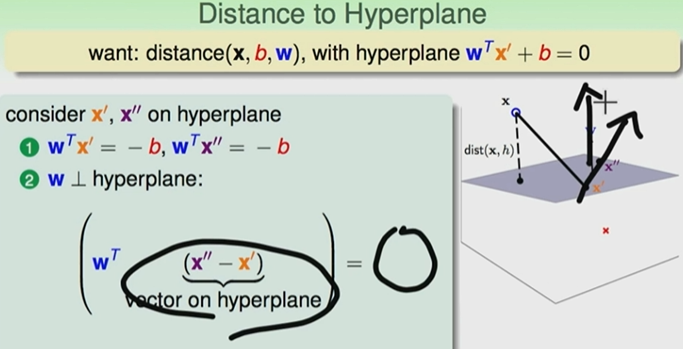
距离怎么计算
首先,分出一个w0,x0,w0可以代表截距;其他的w还是集合在一个向量里面,但是会比原来小;最后公式就变为wx+b=0

那么点到平面的距离:
可以先考虑一个平面的两个点,下面的公式可以看到w是平面(x’‘,x’)所处平面的法向量。
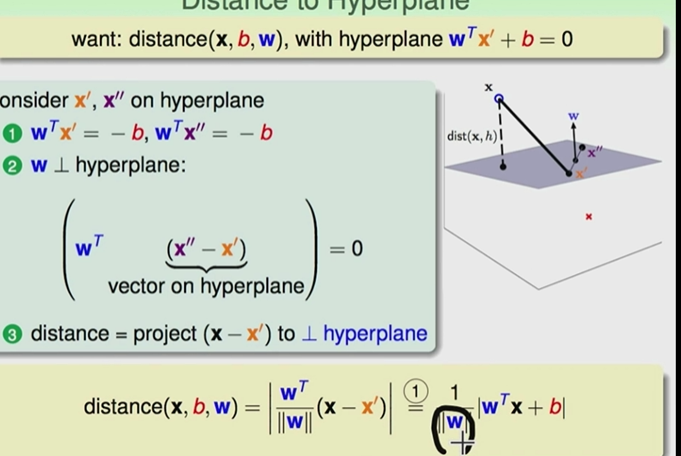
那么我们所要求的点到平面的距离是什么?
可以看到我们所求的x到平面的距离就是,x点与平面上一个点投影到垂直于平面的方向,就是W的方向。
对于可以完美分隔的线还有一个性质
我们算出来的分数与我们想要的分数是同号的,所以两者相乘大于零;

那么我们的公式就可以改写:可以替换成x,y代表的式子,那么绝对值就可以脱掉

继续简化上面的式子:
假设我们最小的 ,那么我们的式子就可以写成
,那么我们的式子就可以写成

如果我们把最小的条件放松,将条件改为>=1,如果最后得到的最佳的解还是落到条件放松之前的区域,那么对于我们的解就没有影响;
如果最佳的解落到了区域外面,没有等于1的值,假设所有的都大于1.126,
 那么 我们得到的就会增大,与前面所说的最佳解矛盾,也就是说我们得到的根本不是最佳解。所以增大条件对我们最佳解没有影响。
那么 我们得到的就会增大,与前面所说的最佳解矛盾,也就是说我们得到的根本不是最佳解。所以增大条件对我们最佳解没有影响。
最终的求解
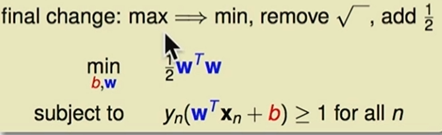
下面用例子讲解

上面求解的过程其实就是SVM的基本想法:
SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。
上面的例子只有四个点所以很好得到解,如果点不止四个,那么该怎么得到最佳的解?可以用二次规划求解》。。。。。。

那么我们要找到的线就要满足下面两个条件:找到合适的线,可以把圈圈叉叉分开的线,计算每条线与点的距离,找到点与线的最小的距离,比较所有的线与点的最小距离,找到最大的值就是最合适的线。
svm R
# svm函数的基本语法及参数解释
> svm(formula, data = NULL, ..., subset, na.action =na.omit, scale = TRUE)
# formula:指定参与分析的变量公式
# subset:为索引向量,指定分析的样本数据
# na.action:针对缺失值的处理方法,默认会删除缺失值所在的行
# scale:逻辑参数,是否标准化变量,默认标准化处理
> svm(x, y = NULL, scale = TRUE, type = NULL, kernel ="radial", degree = 3,
+ gamma = if (is.vector(x)) 1 else 1 / ncol(x),coef0 = 0, cost = 1, nu = 0.5,
+ class.weights = NULL, cachesize = 40, tolerance = 0.001, epsilon = 0.1,
+ shrinking = TRUE, cross = 0, probability = FALSE, fitted = TRUE,...,subset,
+ na.action = na.omit)
# x:可以是矩阵,可以是向量,也可以是稀疏矩阵
# y:分类变量
# type:指定建模的类别,支持向量机通常用于分类、回归和异常值检测,默认情况下,svm模型根据因变量y是否为因子,type选择C-classification或eps-regression
# kernel:指定建模过程中使用的核函数,目的在于解决支持向量机线性不可分问题。函数中有四类核函数可选,即线性核函数、多项式核函数、高斯核函数和神经网络核函数
# degree:用于多项式核函数的参数,默认为3
# gamma:用于除线性核函数之外的所有核函数参数,默认为1
# coef0:用于多项式核函数和神经网络核函数的参数,默认为0
# nu:用于nu-classification、nu-regression和one-classification回归类型中的参数
# class.weights:指定类权重
# cachesize:默认缓存大小为40M
# cross:可为训练集数据指定k重交叉验证
# probability:逻辑参数,指定模型是否生成各类的概率预测,默认不产生概率值
# fitted:逻辑参数,是否将分类结果包含在模型中,默认生成拟合值
##MASS包中的cats数据集共包含三个变量,其中变量Sex表示猫的性别('F'or'M'),Bwt表示猫的体重(单位:kg),Hwt表示猫的心脏重量(单位:g)
>library(e1071)
>library(MASS)
> head(cats)
Sex Bwt Hwt
1 F 2.0 7.0
2 F 2.0 7.4
3 F 2.0 9.5
4 F 2.1 7.2
5 F 2.1 7.3
6 F 2.1 7.6
> index <- sample(2,nrow(cats),replace = TRUE,prob=c(0.7,0.3))
> traindata <- cats[index==1,]
> testdata <- cats[index==2,]
> # 构建模型
> cats_svm_model <- svm(Sex~.,data=traindata)
> cats_svm_model
Call:
svm(formula = Sex ~ ., data = traindata)
Parameters:
SVM-Type: C-classification
SVM-Kernel: radial
cost: 1
Number of Support Vectors: 61
> cats_svm_model_pred_1 <- predict(cats_svm_model,traindata[,-1])
> cats_table_1 <- table(pred=cats_svm_model_pred_1,true=traindata[,1])
> accuracy_1 <- sum(diag(cats_table_1))/sum(cats_table_1)
> accuracy_1
[1] 0.8020833
> # 使用建立好的模型进行预测并查看测试样本的预测情况
> cats_svm_model_pred_2 <- predict(cats_svm_model,testdata[,-1])
> cats_table_2 <- table(pred=cats_svm_model_pred_2,true=testdata[,1])
> cats_table_2
true
pred F M
F 9 5
M 6 28
> accuracy_2 <- sum(diag(cats_table_2))/sum(cats_table_2)
> accuracy_2
[1] 0.7708333
> # 预测结果的可视化展示
> plot(cats_svm_model,testdata)